PHPerKaigi 2026 PHPerコードバトル writeup #2
前回に続き、PHPerKaigi 2026のPHPerコードバトルに私が提出した回答の解説を行っていきます。 ルールやスコア計算に関しては前回の記事を参照して下さい。
前回の記事はこちら: PHPerKaigi 2026 PHPerコードバトル writeup #1
オフライン予選:エキシビション1 - 漢数字
標準入力から行区切りでテキストが入力されます。テキストに含まれる数字を漢数字に置換して出力してください。置換は一桁ずつおこない、数字が連続している場合でも「十」や「百」にはしないでください。
https://t.nil.ninja/phperkaigi/2026/code-battle/golf/5/watch
私の提出コードはこうなりました。スコアは72です。
<?php
echo strtr(fread(STDIN, 99), str_split('〇一二三四五六七八九', 3))
?>
fread() 関数にて標準入力全体を読み込み、strtr() 関数で数値を置き換えています。
strtr に変換規則を与える方法は2つありますが、今回はひとつの配列を渡す方式です。
配列のキーで指定された文字列をそれぞれの値に置き換える、という至ってシンプルな動きをします。
ここで与える配列は str_split() で〇から九までの関数を3バイト区切りにしたものです。
3バイト区切りにする理由ですが、UTF-8ではこれらの文字は3バイトとなるからです。
もちろん、代わりに mb_str_split() を使用しても問題ありません。
そして、結果の配列は [0 => '〇', 1 => '一', ...] という形式になっているため置き換えが可能になる、という結果になります。
この問題は他の方もこの方式で提出されていました。 スコア72のうち、漢数字を並べた文字列を埋め込むだけで30バイトも消費しています。 実は漢数字のコードポイントは全く順番になっていません。これらを圧縮したテーブルを用意する術はほとんどないため、これ以上縮めるのは困難かと思われます。
オフライン予選:エキシビション2 - シーザー暗号
標準入力の最初の行に正の整数 N が与えられます。
また、2 行目以降の各行に英字を含む文字列が与えられます。
各文字を英字アルファベット順で N 文字だけ後ろにずらして出力してください。Z の次は A に戻ります。
大文字は大文字のまま、小文字は小文字のまま変換し、英字以外の文字はそのまま出力します。
N=3 のとき「Hello!」なら「Khoor!」を出力します。
2 行目以降のすべての行についてこの手順を繰り返してください。
N が 26 以上になりうることに注意してください。
入力例: 3 Hello! abc XYZ出力例: Khoor! def ABC
https://t.nil.ninja/phperkaigi/2026/code-battle/golf/6/watch
この問題は入力の最初に与えられた数値の分だけ、アルファベットの大文字、小文字をローテートさせよ、というものです。 大文字は大文字のまま、小文字は小文字のままローテートするのがこの問題の難しいポイントです。
私の提出はスコア94でした。
<?php
for($n=fgets(STDIN);$o=ord(fgetc(STDIN));)
echo chr($o-->64&$o%32<26?($o%32+$n)%26+1|$o&96:$o+1)
?>
禍々しい見た目をしていますが、やってることは1文字ごとに文字コードベースでローテートするかどうかを判定してローテートし出力する、というものです。 ここで、大文字と小文字のローテートは区別せず、どちらにも適用できるロジックで実装しています。これによって分岐が減り、コード量も削減できました。
さて、文字コードベースでローテートする計算処理を見ていきます。chr(...) の内側は概ね以下のようなことを行っています。
- 計算上の都合のため、入力文字コード
$oから 1を減ずる。 $oが大文字または小文字のアルファベットかどうかを判定する- そうであれば、大文字小文字を考慮した上でのローテート処理を行う
- そうでなければ、1を減ずる前の
$oを返す(つまり、なにもしない)
コード片と対応づけると次のようになります。
// $o からデクリメントしつつ、アルファベットの判定処理をする
$o-- > 64 & $o % 32 < 26
// ローテート処理
? ($o % 32 + $n) % 26 + 1 | $o & 96
// 何も処理しない部分
: $o + 1
アルファベットの判定
まず、全体の処理に先んじて $o-- を行っている理由です。
ASCIIコードにおける大文字のアルファベットは A (65) から Z (90)、小文字のアルファベットは a (97) から z (122) です。
表を書くと次のようになります。

見ていただくとわかる通り、それぞれの段の頭に @ (64) と ` (96) が凹む形で現れていることがわかります。
これでは少々扱いづらいので、ASCIIコードから1を引いてみると、アルファベットの部分がぴっちり揃うことになります。
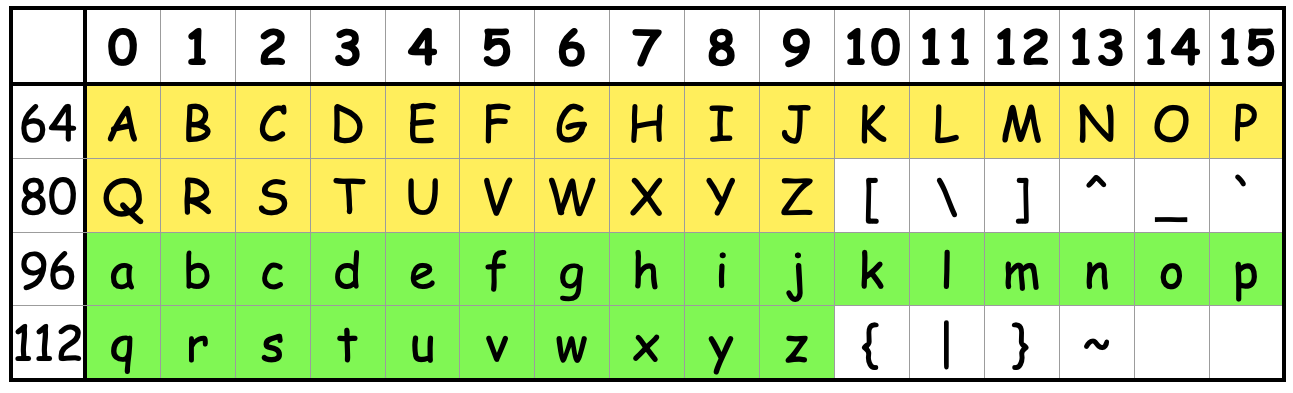
さて、ぴっちり揃うと大文字または小文字の判定は文字コードが64以上かつ、32で割った余りが26未満であるかどうかを見ればできることになります。 これがループの中で最初に行なっていることです(再掲)。
$o-- > 64 & $o % 32 < 26
ローテート
次にローテート処理の部分です。ローテートを行なっている部分を再掲します。
($o % 32 + $n) % 26 + 1 | $o & 96
ここではロジックを圧縮するために大文字と小文字のどちらでも扱えるようにしなければなりません。 基本的な考え方としては、
- 大文字小文字を無視してローテートする
- 大文字小文字の情報を復元する。
- 最初に1引いた分だけ1を足す
といった流れになります。
大文字小文字を無視するというのは、Aもaも0に、Bもbも1に…という具合に、アルファベットを0から25までの数値に対応させることです。
そうすると、ローテート処理が $n を足して 26 で割った余りを取ると記述できます。
実は文字コードから1を引いた状態だと、A や a がちょうど表の左端に来てくれるので $o % 32 という操作で0から25までの数値に対応させることができます。そのため、ローテート処理は以下のようになります。
($o % 32 + $n) % 26
次に、大文字小文字の情報を復元する操作です。ASCIIコード表を睨むと、アルファベット大文字は上3bitが 010, アルファベット小文字は 011 となっています。それを利用し、文字コードの上から2bit目と3bit目を得てビット和を取ればよさそうです。
そのための操作として、 $o & 96 を使っています。
ここで 96 = 64 + 32 = 0100 0000 + 0010 0000 なので要件を満たします。
最後の1を足す操作ですが、演算子の優先順位に注意する必要があります。ここまでの流れを素直に書くと
((($o % 32 + $n) % 26) | ($o & 96)) + 1
となるのですが、 結合の強さは % > + > & > | であるため、このような形で書くと余計なカッコはここまでしか外せません。
(($o % 32 + $n) % 26 | $o & 96) + 1
しかし、ローテートの部分は0から25までの値となるため、そこに1を足しても上位ビットに影響しません。したがって、 + 1 は内側に潜らせて
($o % 32 + $n) % 26 + 1 | $o & 96
と書くと2バイトの節約となります。1
以上で、大文字小文字を保ったままローテートすることができました。あとはアルファベットではなかった場合は $o + 1 を返せばOKです。
最終的に得られた文字コードを chr() 関数に渡し、echo で出力します。全体を再掲するとこうなります。
<?php
for($n=fgets(STDIN);$o=ord(fgetc(STDIN));)
echo chr(
$o-- > 64 & $o % 32 < 26
? ($o % 32 + $n) % 26 + 1 | $o & 96
: $o + 1
)
?>
ちなみに、ループの条件式に ord() を使うと少々都合がいいです。PHPでは "0" は偽という極悪非道な仕様があるので、
for (...; $c = fgetc(STDIN); ...) のようなループを書くと "0" がやってきた途端にループが止まるという緊急異常事態が発生します。
ここに ord() を噛ませることにより、"0" はASCIIコードの 48 (!= false) になってくれるため安心です。
次回はオンライン予選問題1について解説しようと思います。
-
三項演算子を含めて全体をカッコの中に放り込んで、+1を一回省略するという手もありますが、スコアは同じでしょう。 ↩